A new publication has been accepted in the IEEE 34th International Symposium on Computer Architecture and High Performance Computing, titled FiBHA: Fixed Budget Hybrid CNN Accelerator. This conference is located in Bordeaux, France, from November 2 to 5, 2022.
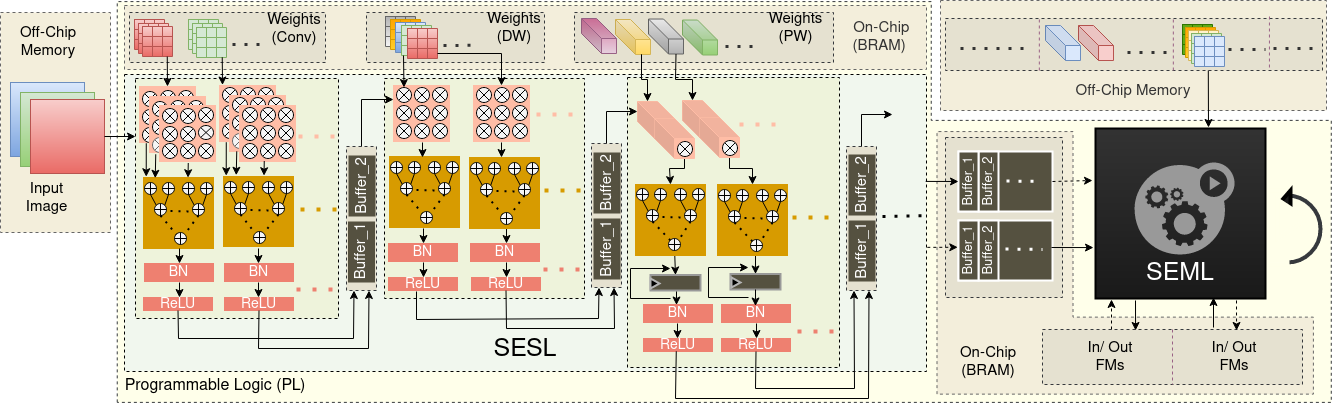
Abstract: Seeking the “sweet spot” in the accuracy-efficiency trade-off is increasing the heterogeneity of state-of-the-art Convolutional Neural Networks (CNNs). Such CNN models exhibit heterogeneity at two levels: intra- and inter-layer-type. Generic accelerators do not capture these levels of heterogeneity. Consequently, researchers have proposed model-specific accelerators with dedicated modules or engines. The proposed accelerators belong to two categories at the two ends of the design spectrum. In the first category, the accelerators contain a minimal number of dedicated engines such that all the layers of one type (e.g. depthwise convolutions) are handled by one engine. In the second, they have one dedicated engine per layer. While the first category addresses the inter-layer-type heterogeneity, it cannot capture the heterogeneity among layers of the same type. The second category is resource-demanding. In this paper, we propose a hybrid architecture that combines design concepts from both categories in a way that captures more heterogeneity than the first category and is more resource-efficient than the second. To derive a hybrid accelerator given a fixed resource budget, we propose a heuristic that splits the CNN and the available resources between the components of the hybrid architecture. The proposed architecture is implemented and evaluated using high-level synthesis (HLS) on an FPGA. For a fixed hardware budget, the hybrid accelerator achieves up to 1.7x and 4.1x of the throughput achieved by state-of-the-art accelerators of the two categories.
The publication is part of an initiative that seeks a more efficient acceleration of CNNs. Efficient acceleration of CNNs is an integral part of VEDLIoT vision of enabling a very-efficient Deep Learning throughout the IoT continuum.